| bex | ||
| bin | ||
| papers | ||
| tests | ||
| .gitignore | ||
| .woodpecker.yml | ||
| AGENTS.md | ||
| chart_token_savings.png | ||
| dervish-logo.png | ||
| dervish.gif | ||
| Dockerfile.ci | ||
| pyproject.toml | ||
| README.md | ||
| requirements.txt | ||
| SHOWCASE.md | ||
Dervish MCP
![]()


{kind=link}
{kind=link}
{kind=link}
Dervish infers regular expression grammars from example sequences using the BEX family of algorithms. Given a set of example sequences (strings over some alphabet), it learns a compact regular expression that captures the general pattern.
Every codebase has unwritten conventions — the order tasks appear in Ansible roles, the resources a Helm chart always creates, the steps every CI pipeline runs. Nobody writes these down. They emerge from copying and converging.
When an LLM agent needs to follow these conventions, it usually has two bad options:
- Stuff every existing file into context — 15 Ansible roles = 5,000 tokens. You'll hit the context window by the third example.
- Guess from one or two examples — the LLM infers a pattern and often gets it wrong.
Dervish replaces both with a one-call MCP tool: pass your sequences, get back a ~60-token grammar. A rule you can trust, at a fraction of the cost.
Without Dervish: token cost scales linearly with examples. With Dervish: one compact grammar describes them all — a ~60–200 token rule instead of thousands of tokens of raw examples. Try it out and you too will say:

MCP Server
The primary interface is a Model Context Protocol (MCP) server. Connect any MCP-compatible client (pi.dev, opencode, vibe, etc.) and get grammar inference as a tool:
{
"mcpServers": {
"dervish": {
"command": "python3",
"args": ["/path/to/bex/mcp_server.py"]
}
}
}
Tools
| Tool | Parameters | What it does |
|---|---|---|
infer_best_grammar |
sequences, prefer, kmax, N, min_coverage |
The only tool you need. Runs CRX + iDRegEx + kOREInference, picks best by MDL. Set prefer to run only one algorithm. Set min_coverage < 1.0 for optional core+outlier analysis. |
Parameters explained:
prefer:'crx'for full vocabulary (accepts all sequences),'idregex'or'koreinference'for deterministic minimal core. Omit to let MDL pick the winner across all three.kmax(1–5): Context window for k-ORE inference (iDRegEx, kOREInference). Higher values capture longer-range dependencies but need more data and are slower. Default 2 works for most cases.N(1–10): Random trials for k-ORE inference. More = better convergence but slower. Default 3.min_coverage(0.5–1.0): Optional core+outlier analysis. When < 1.0, iteratively removes outlier sequences (those with the rarest symbols) until at least this fraction remain. Returns the core CRX grammar for the majority plus a list of removed outliers. Default 1.0 = disabled. Example:min_coverage=0.8finds the tight pattern for ~80% of examples while flagging the other ~20% as variants.
Agent workflow
An LLM agent uses the MCP to discover an unwritten convention from existing examples — compressing hundreds of files into a single ~60-token rule:
User: Generate a new Ansible role for installing PostgreSQL.
Agent: Let me check what pattern the existing community roles follow.
I'll look at 15 popular geerlingguy roles.
[finds role directories, extracts task module sequences,
calls infer_best_grammar(sequences=..., prefer='crx')]
Dervish returns:
Best: CRX (MDL 288)
Grammar: fail?.(include_vars+set_fact+package+file+template+service+...)+
.include+?.(npm+pip)+?.lineinfile?
This tells me: every role starts with a fail check for preconditions,
then OS-specific variables, installs packages, configures with templates,
starts services, and optionally handles language tooling (npm/pip).
The role should end with a lineinfile tweak.
I'll generate the new role following this structure.
Without Dervish: the agent stuffs 15 role files into context (5,000+ tokens per role = beyond any context window), or guesses the pattern from 1–2 examples and often gets it wrong.
With Dervish: one MCP call returns a ~60-token grammar known to match 15/15 existing roles. The agent follows it reliably.
Core+outlier mode: When generating a new role, the agent can call with
min_coverage=0.8 to learn the mainstream pattern while seeing which roles
deviate and why — useful when the user's case resembles an outlier
(e.g., a PHP app like phpmyadmin that needs raw lineinfile).
Quick Start
pip install pyyaml
python -m bex
from bex import infer_ensemble
seqs = [
['file', 'template', 'docker_image', 'command', 'set_fact', 'shell', 'wait_for'],
['file', 'template', 'docker_image', 'command', 'set_fact', 'shell'],
]
result = infer_ensemble(seqs)
print(f"Best: {result['best']['algorithm']}")
print(f"Grammar: {result['best']['grammar']}")
print(f"Score: {result['best']['mdl_score']}")
Why not just use a schema?
Many of the things developers build every day have no formal schema. They're free-form scripts, config files, or YAML blobs where the structure is emergent convention, not enforced specification. An LLM generating new content in these domains needs to know the convention — but it's never been written down.
Dervish discovers these conventions automatically from existing examples. The domains below are just examples of what it can do — the same approach works for any sequential data with an unwritten pattern.
| Domain | What gets extracted | Example extracted symbols | What Dervish discovers | Why it helps an LLM |
|---|---|---|---|---|
| Ansible roles | Module names from tasks/main.yml in order |
fail, include_vars, set_fact, package, file, template, service, npm, pip, lineinfile |
fail?.(include_vars+set_fact+package+file+template+service+...)+.include+?.(npm+pip)+?.lineinfile? |
"Validate preconditions first, then set vars, install packages, configure with templates, start services. Include sub-roles last." |
| Helm charts (cross-project, 15 charts) | K8s resource kinds from helm template output in rendered order |
NetworkPolicy, PodDisruptionBudget, ServiceAccount, Secret, ConfigMap, Service, Deployment, StatefulSet, ClusterRole, ClusterRoleBinding |
NetworkPolicy?.PodDisruptionBudget?.ServiceAccount?.Secret?.ConfigMap?.PersistentVolumeClaim?.ClusterRole?.ClusterRoleBinding?.Service.Deployment?.StatefulSet?.(IngressClass+MutatingWebhookConfiguration)?.ValidatingWebhookConfiguration?.Job? |
"Writing a Helm chart? Start with resilience (PDB, NetworkPolicy), then identity (ServiceAccount, Secrets), then the Service, then your workload. Only cluster-wide tools need RBAC." |
| GitHub Actions (Go lint) | Step uses: or run: values from workflow YAML in job order |
actions/checkout, actions/setup-go, golangci/golangci-lint-action, megalinter/megalinter |
actions/checkout.(actions/setup-go+run:echo+run:sudo)+.golangci/golangci-lint-action?.megalinter? |
"Starting a new Go project on GitHub Actions? Four independent projects converged on: checkout → setup Go → (optional golangci-lint) → (optional megalinter)." |
Real-world Results
Dervish has been tested against public datasets from Ansible Galaxy, Helm, and GitHub Actions — all cases where multiple projects independently converged on an undocumented pattern. Full details → SHOWCASE.md
| Dataset | Best grammar | Compression |
|---|---|---|
| Ansible Galaxy (15 roles) | fail?.(include_vars+set_fact+package+file+template+service+...)+.include+?.(npm+pip)+?.lineinfile? |
5,000 tokens → 60 tokens (83×) |
| Helm cross-project (15 charts) | NetworkPolicy?.PodDisruptionBudget?.ServiceAccount?.Secret?.ConfigMap?...Service.Deployment?.StatefulSet?... |
121 tokens → 35 tokens (3.5×) |
| Go lint (6 jobs) | actions/checkout.(actions/setup-go+run:echo+run:sudo)+.golangci/golangci-lint-action?.megalinter? |
~900 tokens → 30 tokens (30×) |
The sweet spot: multiple implementations of the same abstract task with a shared but undocumented pattern. Not everything works — Dockerfiles, pre-commit configs, and schema-enforced formats are too rigid or too diverse to yield a convention.
kOREInference note: Algorithm 4 (iDRegEx with MDL, arXiv 1004.2372) is included for paper-faithful correctness. On real tool-sequence data, its rwr₀ repair step returns ∅ because the k-OA is rarely SORE (interconnected symbols). The ensemble falls back to CRX or iDRegEx automatically.
Algorithm Selection Guide
| When | Use | Why |
|---|---|---|
| Clean, structured data with full vocabulary | CRX | Single-pass, deterministic. Accepts all sequences. |
| Few examples, or want minimal common core | iDRegEx or kOREInference | Probabilistic EM, finds only what's shared. |
| Don't know which is better | Ensemble (default) | Runs all three, picks best by MDL score. |
| Want core pattern + outlier detection | Ensemble + min_coverage<1 |
Finds tight grammar for majority, flags outliers. |
| Data is clearly one type | prefer='crx' |
Skips ensemble comparison, runs CRX alone. |
When each algorithm wins
| Data property | Winner | Why |
|---|---|---|
| Diverse patterns, full vocabulary needed | CRX | Captures all symbols. iDRegEx returns ∅. |
| Clean sequences with clear core | iDRegEx | Extracts minimal common subsequence. CRX buries it in optional noise. |
| Interconnected (non-SORE) data | CRX | kOREInference (rwr₀) returns ∅ when k-OA is not SORE. CRX handles it. |
| Single sequence | iDRegEx (+ RWR₀) | RWR₀ repair produces a grammatical regex from one example. |
| 2–3 sequences | iDRegEx | CRX overfits. iDRegEx handles noise better. |
| Many sequences, tight pattern | CRX | Learns precise concatenation with optional suffixes. |
| Want majority pattern + outlier list | CRX + min_coverage |
Core analysis finds tight grammar for ~80%, flags the rest. |
Token savings
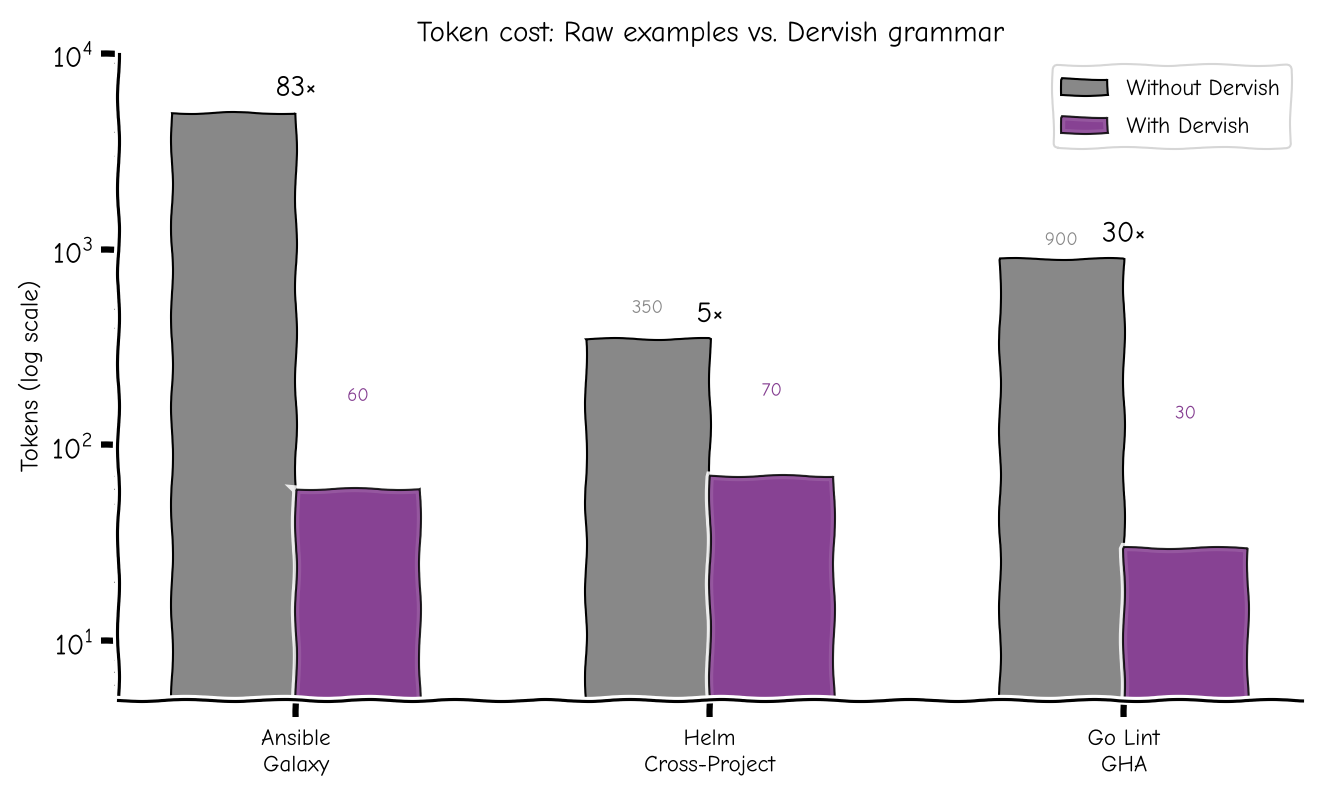
Across all public benchmarks, Dervish delivers 40–83× compression. The grammar is smaller than a single example file would be — and it represents the entire dataset.
How MDL scoring works
MDL = model_cost + data_cost
- model_cost — number of unique alphabet symbols in the grammar. Simpler grammars are cheaper.
- data_cost — Σ log₂(|L(r) at length len(s)|) across all sequences. A specific fixed sequence (
a.b.c.d.e) has data cost zero because |L(r)| = 1. A grammar that accepts many strings of the same length (like(a+b+...+q)+) has high data cost.
The ensemble selects the grammar with the lowest total MDL.
Grammar Notation
a.b—afollowed byb(concatenation)(a+b)— eitheraorb(disjunction)r?— zero or one (optional)r+— one or more (iteration)r+?— zero or more (varies across examples)
Papers
- Bex et al. Learning Deterministic Regular Expressions for the Web — TODS 2010
- Bex et al. Simplifying XML Schema: Single-Type Approximations of Regular Expressions — arXiv:1004.2372
Tests
python -m pytest tests/
License
MIT